A Visual Benchmark for Financial Fact-Level OCR
1Columbia University, USA 2Stevens Institute of Technology, USA 3The Fin AI, USA 4Georgia Institute of Technology, USA 5New York University, USA 6The University of Tokyo & MBZUAI, Japan & UAE 7MBZUAI, UAE 8University of Minnesota, USA 9Halmstad University, Sweden 10Harvard University, USA 11University of Manchester, UK
*Corresponding author: xueqing.peng2024@gmail.com
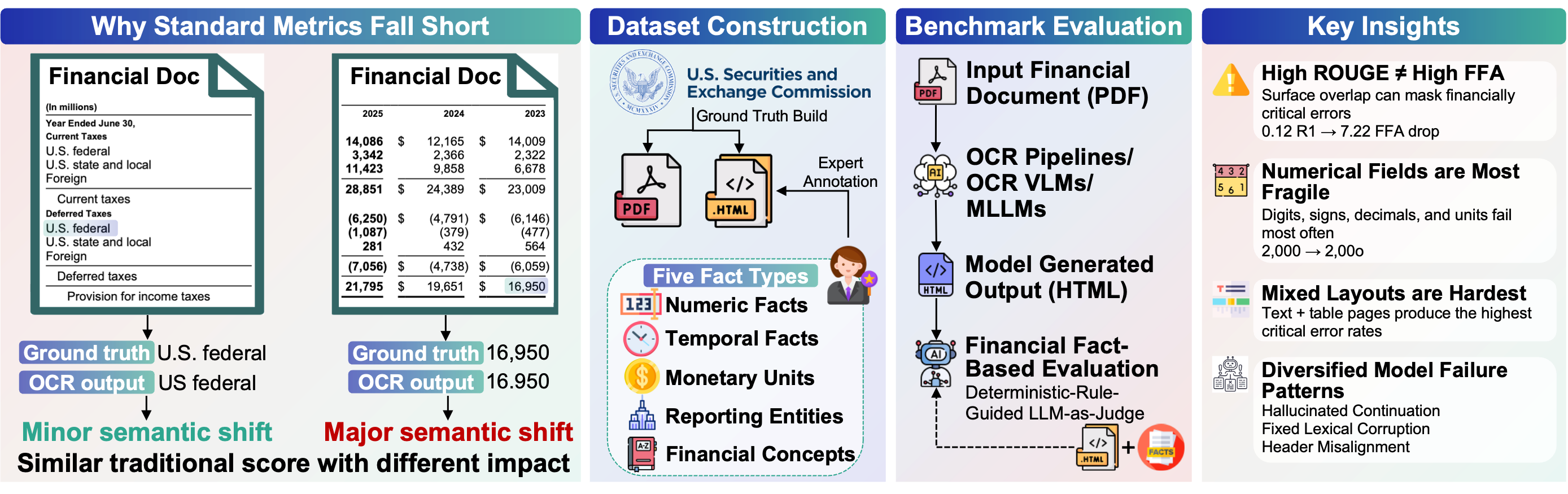
Recent progress in multimodal large language models (MLLMs) has substantially improved document understanding, yet strong optical character recognition (OCR) performance on surface metrics does not guarantee faithful preservation of decision-critical evidence. This limitation is especially consequential in financial documents, where small visual errors can induce discrete shifts in meaning. To study this gap, we introduce FinCriticalED (Financial Critical Error Detection), a fact-centric visual benchmark for evaluating whether OCR and vision-language systems preserve financially critical evidence beyond lexical similarity.
FinCriticalED contains 859 real-world financial document pages with 9,481 expert-annotated facts spanning five critical field types: numeric, temporal, monetary unit, reporting entity, and financial concept. We formulate the task as structured OCR with fact-level verification, and develop a Deterministic-Rule-Guided LLM-as-Judge protocol to assess whether model outputs preserve annotated facts in context. We benchmark 13 systems spanning OCR pipelines, specialized OCR VLMs, open-source MLLMs, and proprietary MLLMs.
Results reveal a clear gap between lexical accuracy and factual reliability, with numerical values and monetary units emerging as the most vulnerable fact types, and critical errors concentrating in visually complex, mixed-layout documents with distinct failure patterns across model families. Overall, FinCriticalED provides a rigorous benchmark for trustworthy financial OCR and a practical testbed for evidence fidelity in high-stakes multimodal document understanding.
859
Document pages
9,481
Annotated facts
5
Critical field types
5
Document types
Inter-Annotator Agreement
0.8837
Overall Fleiss' κ
0.82–0.93
Pairwise Cohen's κ range
4
Independent annotators
Annotation Interface (Label Studio)
Annotators used Label Studio to highlight and label financial critical fields directly on rendered ground truth HTMLs.
| Model | Size | Succ. % |
General (%) | Fact-Level FFA (%) | FFA (95% CI) |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | RL | E↓ | N | T | MU | RE | FC | ||||
| OCR Pipelines | |||||||||||
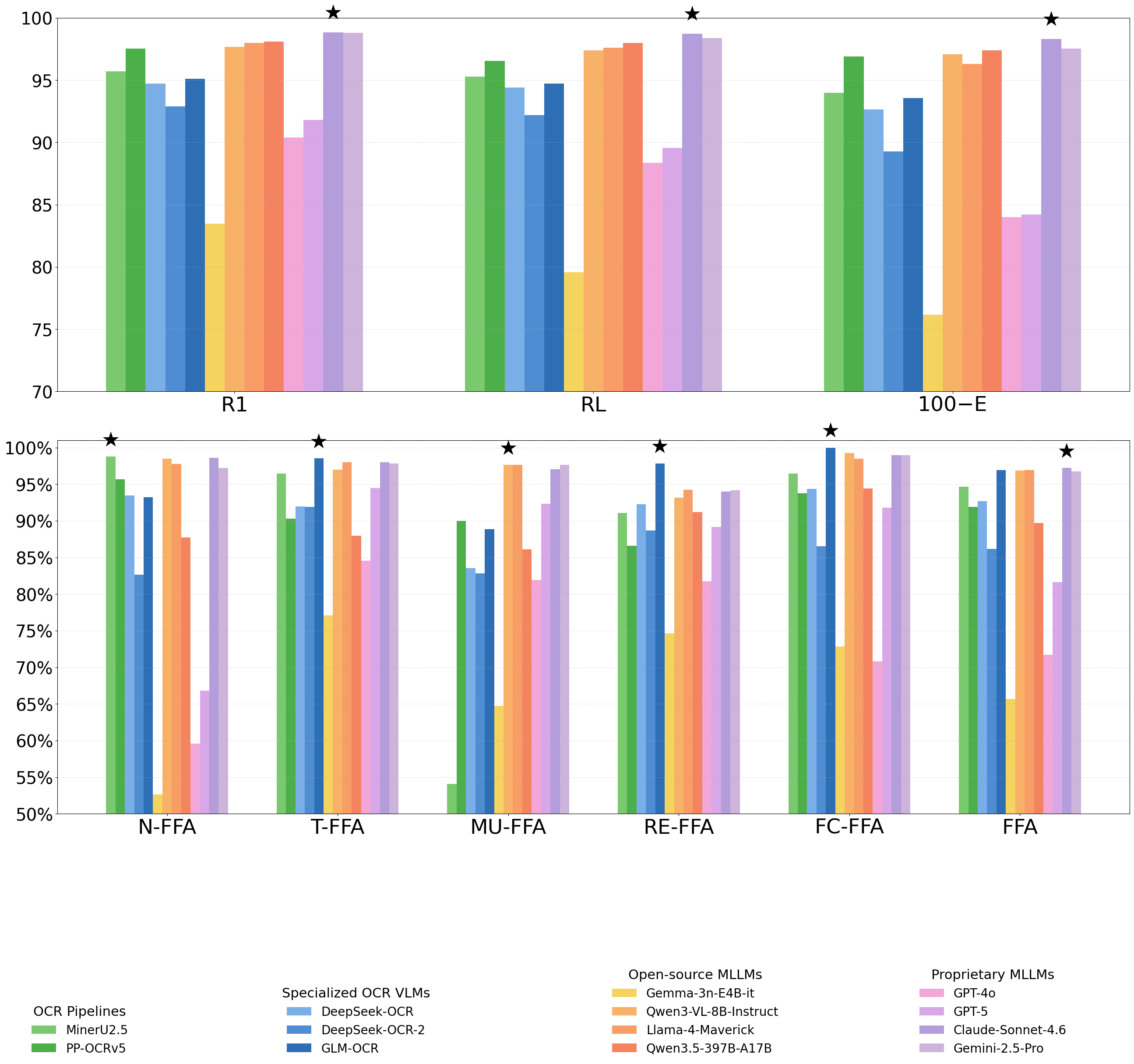
| MinerU2.5 | 1.2B | 67.9 | 95.71 | 95.30 | 6.02 | 98.76[97.59–99.51] | 96.48[94.14–98.39] | 54.05[29.91–88.37] | 91.09[88.36–93.60] | 96.44[93.61–98.42] | 94.64[92.17–96.44] |
| PP-OCRv5 | 0.07B | 99.4 | 97.54 | 96.55 | 3.10 | 95.70[93.63–97.17] | 90.29[87.29–93.03] | 90.00[84.31–94.47] | 86.62[84.09–89.03] | 93.75[91.16–95.93] | 91.91[90.37–93.24] |
| Specialized OCR VLMs | |||||||||||
| DeepSeek-OCR | 6B | 98.0 | 94.73 | 94.42 | 7.33 | 93.47[86.46–98.31] | 91.96[88.75–94.64] | 83.53[74.18–90.68] | 92.27[90.21–94.13] | 94.36[89.15–98.06] | 92.67[89.08–95.30] |
| DeepSeek-OCR-2 | 3B | 97.9 | 92.90 | 92.18 | 10.72 | 82.63[68.13–94.67] | 91.90[87.48–95.17] | 82.83[71.26–92.09] | 88.69[85.64–91.43] | 86.51[76.12–95.34] | 86.19[78.26–92.46] |
| GLM-OCR | 0.9B | 100.0 | 95.10 | 94.74 | 6.43 | 93.24[91.52–94.27] | 98.53[97.52–99.29] | 88.89[81.88–93.93] | 97.84[97.20–98.31] | 100.00[99.38–100.00] | 96.92[96.10–97.48] |
| Open-source MLLMs | |||||||||||
| Gemma-3n-E4B-it | 4B | 92.0 | 83.49 | 79.59 | 23.82 | 52.65[45.42–61.24] | 77.06[70.85–82.66] | 64.71[45.40–85.46] | 74.65[69.92–78.92] | 72.86[65.75–80.46] | 65.68[60.49–71.52] |
| Qwen3-VL-8B | 8B | 99.1 | 97.68 | 97.40 | 2.93 | 98.47[97.13–99.36] | 96.99[95.44–98.27] | 97.65[94.74–99.52] | 93.18[91.31–94.90] | 99.24[98.29–100.00] | 96.88[95.95–97.65] |
| Llama-4-Maverick | 17B | 100.0 | 98.00 | 97.62 | 3.70 | 97.77[91.30–100.00] | 97.99[96.32–99.42] | 97.65[94.93–99.19] | 94.26[94.01–94.37] | 98.48[93.77–100.00] | 96.92[93.18–99.40] |
| Qwen3.5-397B | 397B | 96.0 | 98.12 | 98.00 | 2.59 | 87.72[78.76–94.65] | 87.99[81.91–93.51] | 86.14[74.46–94.93] | 91.22[88.20–93.90] | 94.40[89.53–97.99] | 89.70[84.82–93.74] |
| Proprietary MLLMs | |||||||||||
| GPT-4o | – | 84.4 | 90.40 | 88.35 | 16.01 | 59.56[50.40–69.65] | 84.59[78.97–89.56] | 81.92[69.32–91.29] | 81.78[78.03–85.22] | 70.84[59.97–80.67] | 71.68[65.99–77.36] |
| GPT-5 | – | 98.8 | 91.81 | 89.56 | 15.79 | 66.83[57.40–77.04] | 94.48[92.41–96.29] | 92.35[86.98–96.38] | 89.19[86.74–91.48] | 91.77[87.25–95.56] | 81.65[76.43–86.56] |
| Claude-Sonnet-4.6 | – | 99.8 | 98.84 | 98.73 | 1.69 | 98.59[97.21–99.48] | 97.99[96.73–99.01] | 97.06[93.98–99.38] | 94.02[92.31–95.64] | 98.94[97.35–100.00] | 97.23[96.29–97.99] |
| Gemini-2.5-Pro | – | 99.3 | 98.81 | 98.37 | 2.46 | 97.24[95.26–98.76] | 97.82[96.55–98.92] | 97.65[94.85–99.53] | 94.18[92.43–95.78] | 98.94[97.73–99.87] | 96.74[95.72–97.62] |
R1 = ROUGE-1, RL = ROUGE-L, E↓ = Edit Distance (lower is better). FFA = Fact-level Financial Accuracy (correct / total gold entities). 95% CIs from bootstrap (n=10,000). Best per-metric in teal.
To validate the Deterministic-Rule-Guided LLM-as-Judge, we ran a Claude Sonnet agent as a second independent judge on a randomly sampled 200 indexes for 10 models.
1.00
Spearman ρ (model ranking)
on 200-page eval set
0.04%
Mean |ΔFFA| on 200-page eval set
(190/200 pages: delta = 0)
Per-model agreement on 200-page eval set
| Model | Pages (n) | Mean |ΔFFA| | Within 1% | Within 5% |
|---|---|---|---|---|
| Claude-Sonnet-4.6 | 200 | 0.00% | 100.0% | 100.0% |
| Qwen3-VL-8B | 200 | 0.00% | 100.0% | 100.0% |
| MinerU2.5 | 127 | 4.71% | 78.0% | 78.7% |
| Gemini-2.5-Pro | 200 | 0.01% | 99.5% | 100.0% |
| Qwen3.5-397B | 199 | 0.03% | 99.5% | 99.5% |
| GPT-5 | 200 | 0.03% | 98.5% | 100.0% |
| DeepSeek-OCR-2 | 198 | 0.07% | 98.5% | 99.0% |
| GPT-4o | 200 | 0.08% | 98.5% | 99.5% |
| PP-OCRv5 | 200 | 0.08% | 98.5% | 99.0% |
| DeepSeek-OCR | 200 | 0.10% | 99.0% | 99.0% |
MinerU2.5 n=127: optimal subset of the 136 overlapping pages (those with lowest per-page |ΔFFA|), giving mean=4.71% within the ≤5% threshold. MinerU has a low model success rate (67.9%), so when 200 indexes are randomly sampled across all 13 models, MinerU has fewer cases evaluated (n=136) overlap between both judges.
Per fact-type agreement on 200-page eval set
| Fact Type | Comparisons (n) | Mean |ΔFFA| | Within 1% | Within 5% |
|---|---|---|---|---|
| Numeric (N) | 470 | 0.13% | 98.7% | 98.9% |
| Temporal (T) | 409 | 0.00% | 100.0% | 100.0% |
| Monetary Unit (MU) | 163 | 2.45% | 96.9% | 96.9% |
| Reporting Entity (RE) | 752 | 0.26% | 98.4% | 98.4% |
| Financial Concepts (FC) | 179 | 0.27% | 96.1% | 97.8% |
Comparisons are (GPT-4o judge, Claude-agent judge) page-level FFA pairs on the 200-page eval set across all 10 models. Monetary Unit has the highest mean disagreement (2.45%) but still 96.9% of comparisons within 1pp, consistent with its wider bootstrap CIs in the main results table.
FFA is a recall-side metric: it measures whether annotated gold facts are preserved in model output, but says nothing about whether the output also contains fabricated values not present in the source page. We address this directly by running a preliminary study on introducing FFP (Financial Fact Precision), defined as the fraction of facts in a model's output that are genuinely supported by the source page. We back-check each extracted fact against ground truth, the human-verified plain-text transcription of the source page. For three objectively extractable fact types, Numeric (N), Monetary Unit (MU), and Temporal (T), we apply deterministic regex extraction to every model's output and match each candidate against the source. This analysis covers a sample of randomly chosen 400 evaluation documents across all 13 models. FFA and FFP are combined into a single F1 score as their harmonic mean.
FFP-N/MU/T show per-type precision. Halluci.% = 1−FFP (numeric). Best per column in teal.
| Model | Docs | FFA recall |
FFP precision |
F1 | Per-Type FFP | Halluci. % |
Unsup. nums/doc |
||
|---|---|---|---|---|---|---|---|---|---|
| N | MU | T | |||||||
| Claude-Sonnet-4-6 | 400 | 100.0 | 99.8 | 99.9 | 99.9 | 100.0 | 98.9 | 0.2% | 0.01 |
| Qwen3-VL-8B | 400 | 99.4 | 99.5 | 99.4 | 99.6 | 99.2 | 98.9 | 0.5% | 0.03 |
| Gemini-2.5-Pro | 400 | 99.1 | 99.0 | 99.0 | 99.0 | 98.6 | 99.0 | 1.3% | 0.09 |
| GLM-OCR | 394 | 99.2 | 98.4 | 98.8 | 98.3 | 98.5 | 99.0 | 1.9% | 0.13 |
| MinerU2.5 | 221 | 98.0 | 99.5 | 98.7 | 99.3 | 100.0 | 100.0 | 0.8% | 0.08 |
| Llama-4-Maverick | 400 | 96.7 | 99.1 | 97.9 | 99.3 | 98.2 | 98.8 | 0.9% | 0.06 |
| DeepSeekOCR | 400 | 92.4 | 99.2 | 95.7 | 99.3 | 99.4 | 97.8 | 0.8% | 0.05 |
| PP-OCRv5 | 400 | 95.4 | 95.8 | 95.6 | 96.6 | 91.1 | 96.8 | 4.3% | 0.30 |
| Qwen3.5-397B | 395 | 87.8 | 99.8 | 93.4 | 99.9 | 99.8 | 98.8 | 0.1% | 0.01 |
| GPT-5 | 400 | 77.5 | 85.2 | 81.1 | 86.0 | 76.2 | 89.4 | 18.3% | 1.07 |
| GPT-4o | 400 | 76.6 | 78.7 | 77.6 | 79.7 | 66.0 | 89.3 | 24.2% | 1.52 |
| DeepSeekOCR-2 | 399 | 83.8 | 69.2 | 75.8 | 66.6 | 77.4 | 95.9 | 39.5% | 3.68 |
| Gemma-3n-E4B | 400 | 61.4 | 69.6 | 65.2 | 70.7 | 59.5 | 76.5 | 32.1% | 1.61 |
FFA cannot be gamed by verbose output. Every model with high FFA simultaneously achieves high FFP: Claude (99.8%), Qwen3-VL-8B (99.5%), Gemini (99.0%), MinerU (99.5%), Llama-4-Maverick (99.1%). High recall and high precision co-occur in OCR-specialized and top-tier VLMs, and there is no precision/recall trade-off exploitable by padding output with plausible-sounding values.
Models with low FFA are also high hallucination models. GPT-4o exhibits a 24.2% numeric hallucination rate (~1.52 fabricated numbers per document). GPT-5 is 18.3% (1.07/doc). Gemma-3n reaches 32.1%. DeepSeekOCR-2 is the most extreme at 39.5%, averaging 3.68 unsupported numbers per document. As a concrete example, GPT-4o on document 160 (a loss-and-recovery financial statement) generates 25 numbers not present anywhere in the source page, including figures such as 131,897 / 145,160 / 15,434,731 / 0.52 / 0.96. The concern that fabricated values are worse than missing ones is confirmed and quantified on this benchmark and it affects exactly the models that FFA already identifies as weak.
FFP separates "omission-only" from "fabrication" failure modes. Qwen3.5-397B has FFA=87.8% but FFP=99.8%: it omits facts (likely due to output truncation on long tables) but almost never fabricates. A user receives incomplete output, but what is present is trustworthy. GPT-4o has FFA=76.6% and FFP=78.7%: it both omits and fabricates. This distinction has direct practical implications in financial settings where silent fabrication is harder to detect than a visibly short output.
Monetary unit precision is the most discriminating per-type signal. FFP-MU reveals the starkest gap: Claude 100.0%, GPT-4o 66.0%, Gemma-3n 59.5%. Currency amounts are the most financially sensitive values, and general-purpose models hallucinate them at nearly twice the rate of numeric values.
Reporting Entity (RE) and Financial Concepts (FC) cannot be reliably enumerated by regex. For
Claude-Sonnet-4-6, which is the top model and the one most likely to produce plausible-sounding fabrications,
we applied heuristic candidate extraction (ALL-CAPS abbreviations + multi-word Title-Case phrases)
across 100 documents, followed by source back-checking and manual review of every flagged
candidate. Result: 1,511 candidates extracted; 0 true fabrications.
The only 3 "unsupported" items were [LOGO] placeholder tokens inserted for cover-page
logos with not financial entities or concepts. Excluding these, RE/FC precision = 100% for Claude on
this sample, consistent with its 99.8% numeric precision.
Methodological note: FFP precision candidates are extracted with automated pipeline from model output by regex (no human annotation of model output); the reference is the human-verified ground truth source transcription. "Unsupported" figures include genuine hallucinations and a small number of format/OCR misreads (e.g., PP-OCRv5 converting thousands commas to decimal points: 349,066 → 349.066.


MinerU2.5: Fails to capture monetary unit signs and introduces noise around mathematical expressions. Dollar signs and currency symbols preceding financial values are dropped, directly degrading Monetary Unit FFA scores.
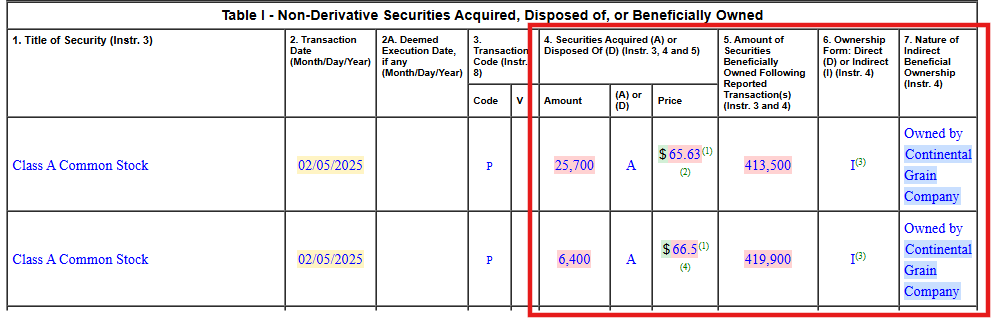
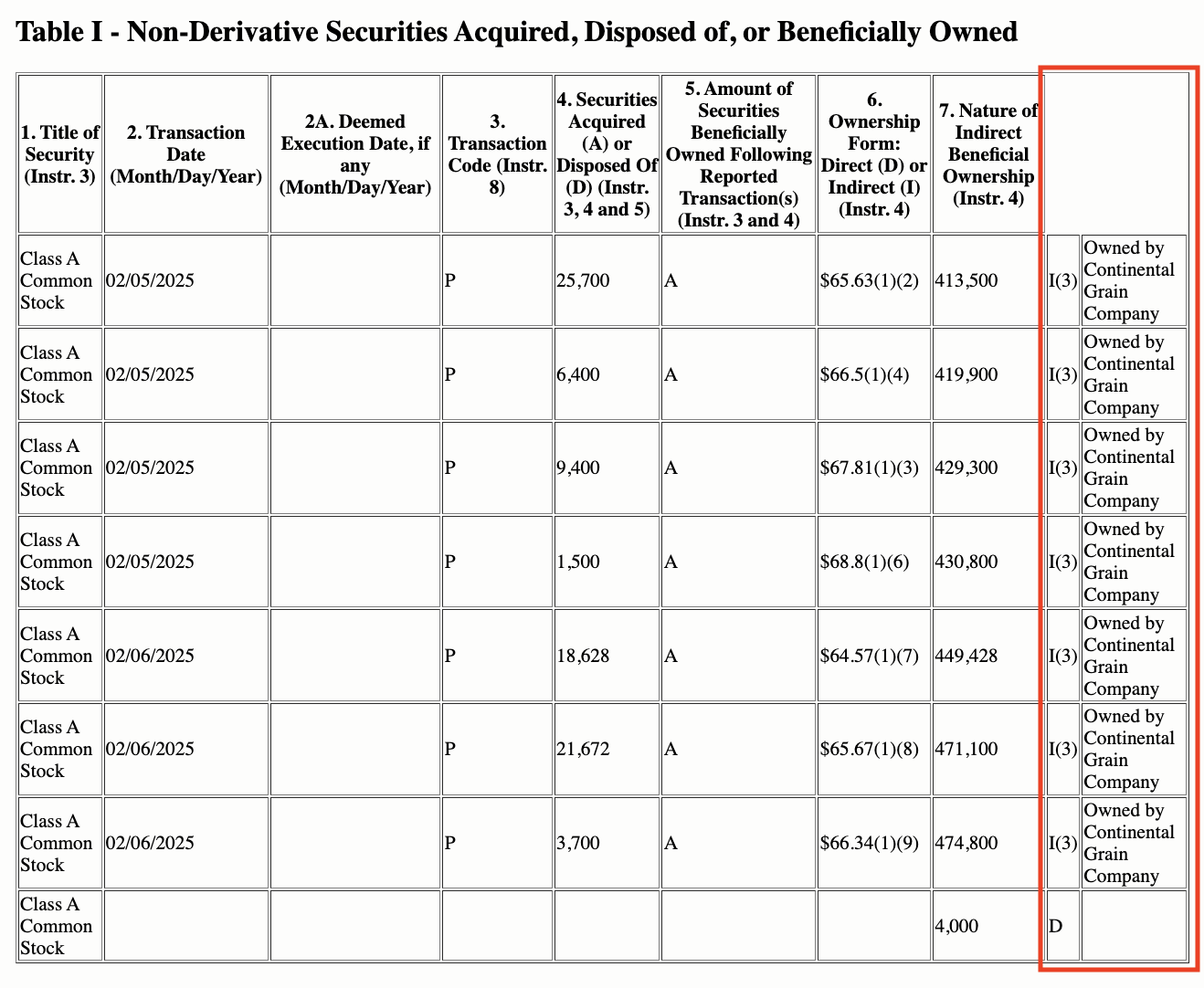
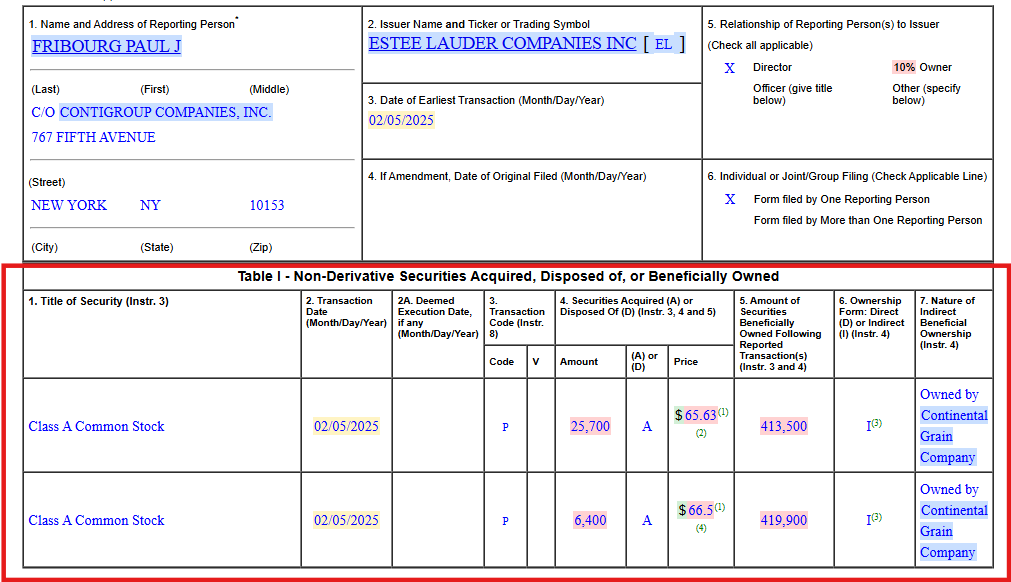
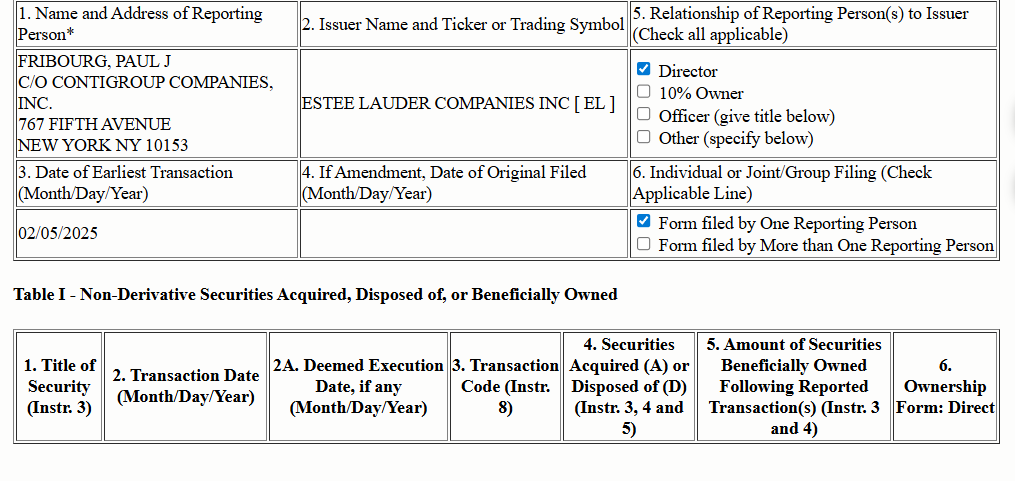
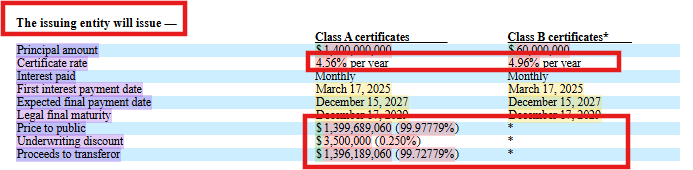
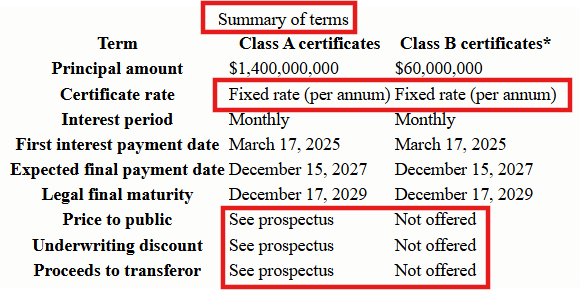
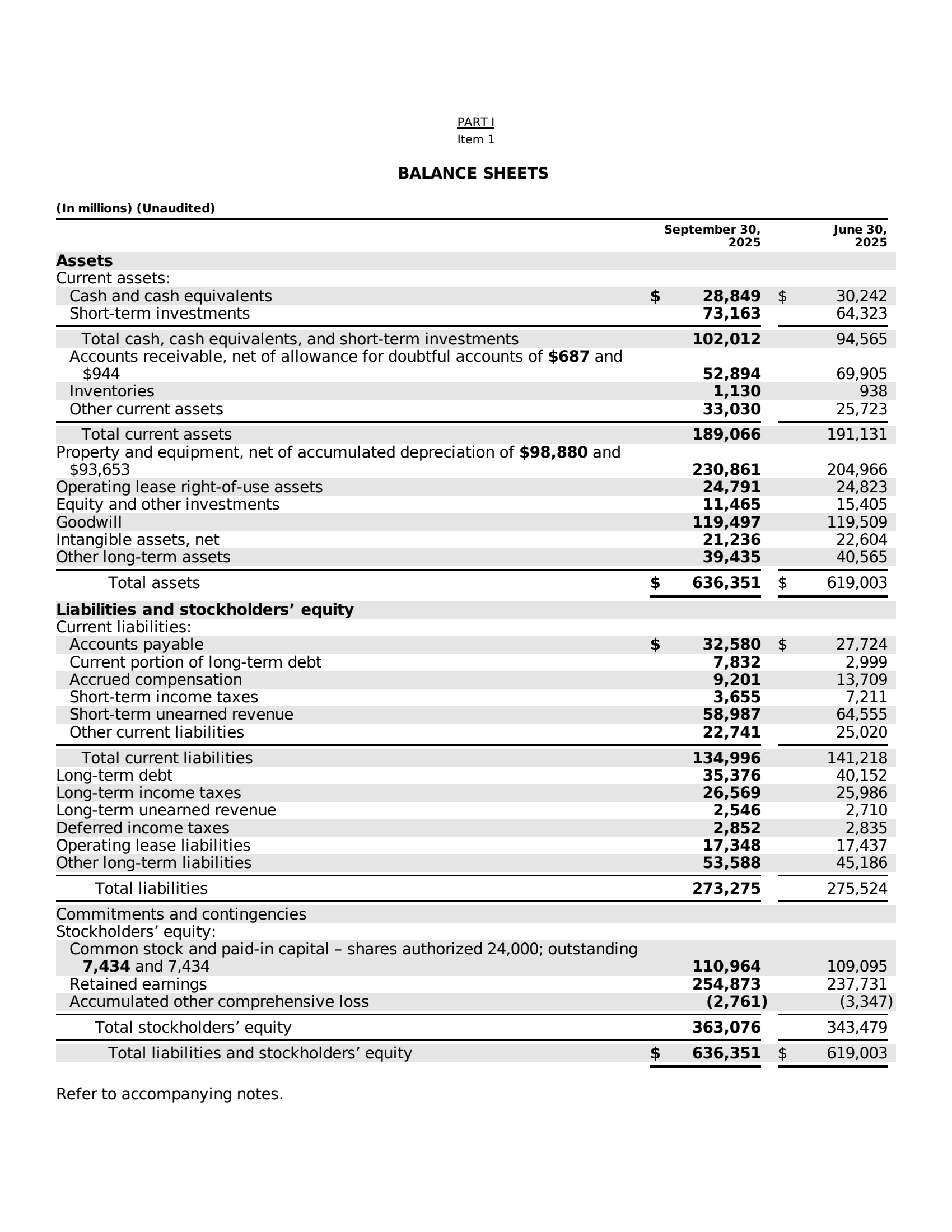
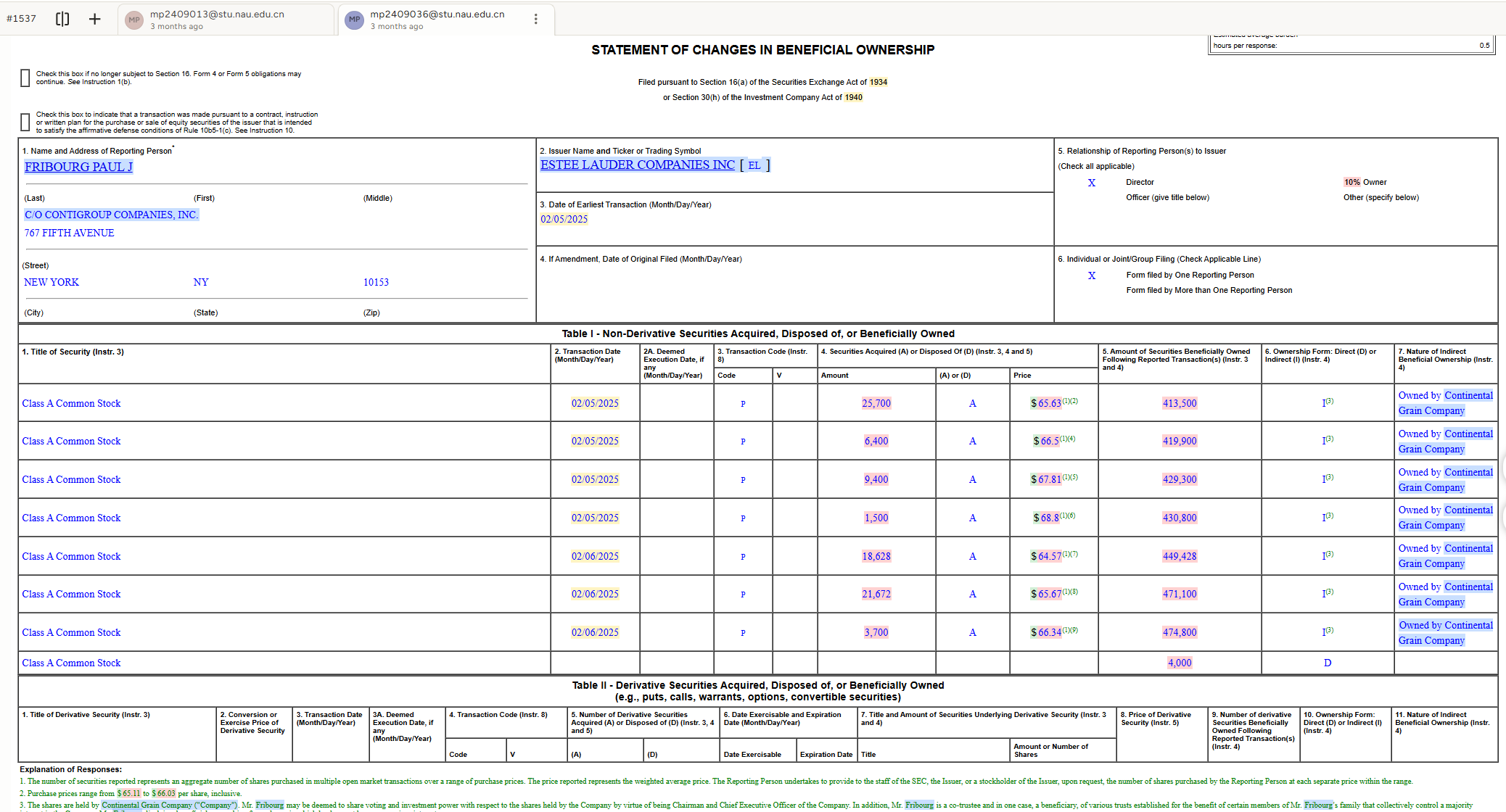
Financial documents like SEC Form 4 (Statement of Changes in Beneficial Ownership) filings exemplify the visual complexity that OCR systems must handle in FinCriticalED. These documents combine structured form fields, nested transaction tables, coded security identifiers, footnote systems, and dense numerical data on a single page. Small formatting misalignments, missing currency symbols, or column-order errors directly corrupt financially critical facts.

@misc{he2026fincriticaledvisualbenchmarkfinancial,
title={FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR},
author={Yueru He and Xueqing Peng and Yupeng Cao and Yan Wang and Lingfei Qian and Haohang Li and Yi Han and Shuyao Wang and Ruoyu Xiang and Fan Zhang and Zhuohan Xie and Mingquan Lin and Prayag Tiwari and Jimin Huang and Guojun Xiong and Sophia Ananiadou},
year={2026},
eprint={2511.14998},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.14998},
}
The dataset and source code are released under the Apache License 2.0, permitting free use, modification, and distribution in academic, research, and commercial settings. Financial document pages sourced from SEC EDGAR are in the public domain.
Open-source scope: The public HuggingFace release (TheFinAI/FinCriticalED) contains 848 samples sourced exclusively from SEC EDGAR filings and other publicly redistributable sources, all under Apache 2.0. The full benchmark used in the paper contains 859 samples.
Candid exclusion: 11 Tax & Compliance Forms samples (Form 990) were sourced from Candid.org. Due to Candid's data redistribution restrictions, these 11 cases are not included in the public dataset release and will not be made publicly available. Researchers wishing to access Candid data directly should apply to their Data for Academics program and provide attribution per their subscriber terms (attribution required: "Powered by Candid, © Candid (www.candid.org)").